By post thirty, something had quietly broken. The output was technically complete. It was still wrong.
The Content Quality Scorecard
- The Volume Trap: If you’re publishing 50+ posts a week with only “light human skimming,” you aren’t scaling—you’re just automating pattern drift.
- Invisible Correction Cost: Calculate the labor wasted on correcting “plausible but garbage” content after it’s already live.
- Automated Gatekeeping: Why a scoring rubric is 10x more effective than a higher model temperature at preventing “AI-flavored” prose.
- Profit Protection: Don’t pay for humans to read everything; pay them to fix only the 20% that your QA agent flags as high-risk.
Decision Snapshot
Best for: Teams scaling AI content past 20 posts per cycle who are losing time to invisible manual correction
Avoid if: Your workflow changes every two weeks — QA gates need a stable process to score against
Reality: The QA agent setup takes longer than expected; the hard part is defining what “quality” actually means in your context
Verdict: Not an AI problem. A process architecture problem. The fix is upstream, not in the model settings.
The Wrong Diagnosis
The natural assumption when output degrades at scale is that the model is to blame. Context window exhaustion. Prompt drift. Model temperature creeping up. These are the things people check first.
That was the wrong diagnosis.
The actual cause: manual review became impossible at volume, so it got quietly dropped. No announcement. No decision. It just stopped happening because there were too many posts to check individually. The model kept generating. The pipeline kept staging. The garbage kept shipping.
The model did not break. The oversight layer did.
This is the pattern that kills most scaled content operations. The automation works fine in isolation. But automation at scale requires automated quality control, and that part almost always gets skipped because it feels like extra work during the build phase.
Check this first before touching any model settings: Open your last 10 published posts. Count how many had a human review step with a documented pass/fail outcome. If the answer is zero, the model is not the problem.
What Pattern Drift Actually Looks Like
Pattern drift is not dramatic. It does not look like obvious failure. That is what makes it dangerous.
It looks like: posts that are technically complete but slightly off-tone. Intros that answer the question before creating any tension. Section headers that describe rather than guide. Conclusions that repeat the intro in different words. Nothing that would trigger a flag on a quick skim, but everything that makes the reader feel like the content was assembled rather than written.
By the time someone notices the traffic signal or the engagement drop, the drift has been compounding for weeks. The individual posts are not obviously bad. The pattern across them is.
Searching this keyword space on page one reveals something consistent: the content that ranks is not necessarily the most comprehensive. It is the most coherent over time. Sites that scaled fast and drifted fast are visible in the SERP graveyard — still indexed, rarely clicked. The comparison and listicle-style results that dominate tend to come from operations that built review gates early, not ones that optimized for volume.
Diagnostic step: Pull five posts from your last production cycle. Read the first paragraph of each. If they all open with the same structural rhythm — problem statement, then definition, then list — you have pattern drift baked into your prompt, not your model.
Before and After: What the Workflow Actually Changed
Before: No QA Gate
The flow looked like this: brief → draft agent → light human skim → staging → publish. The human skim step was the problem. At low volume it was meaningful. At scale it became a scroll-and-approve reflex. Nobody had time to actually read. The posts that went out looked fine at a glance and drifted badly on closer inspection.
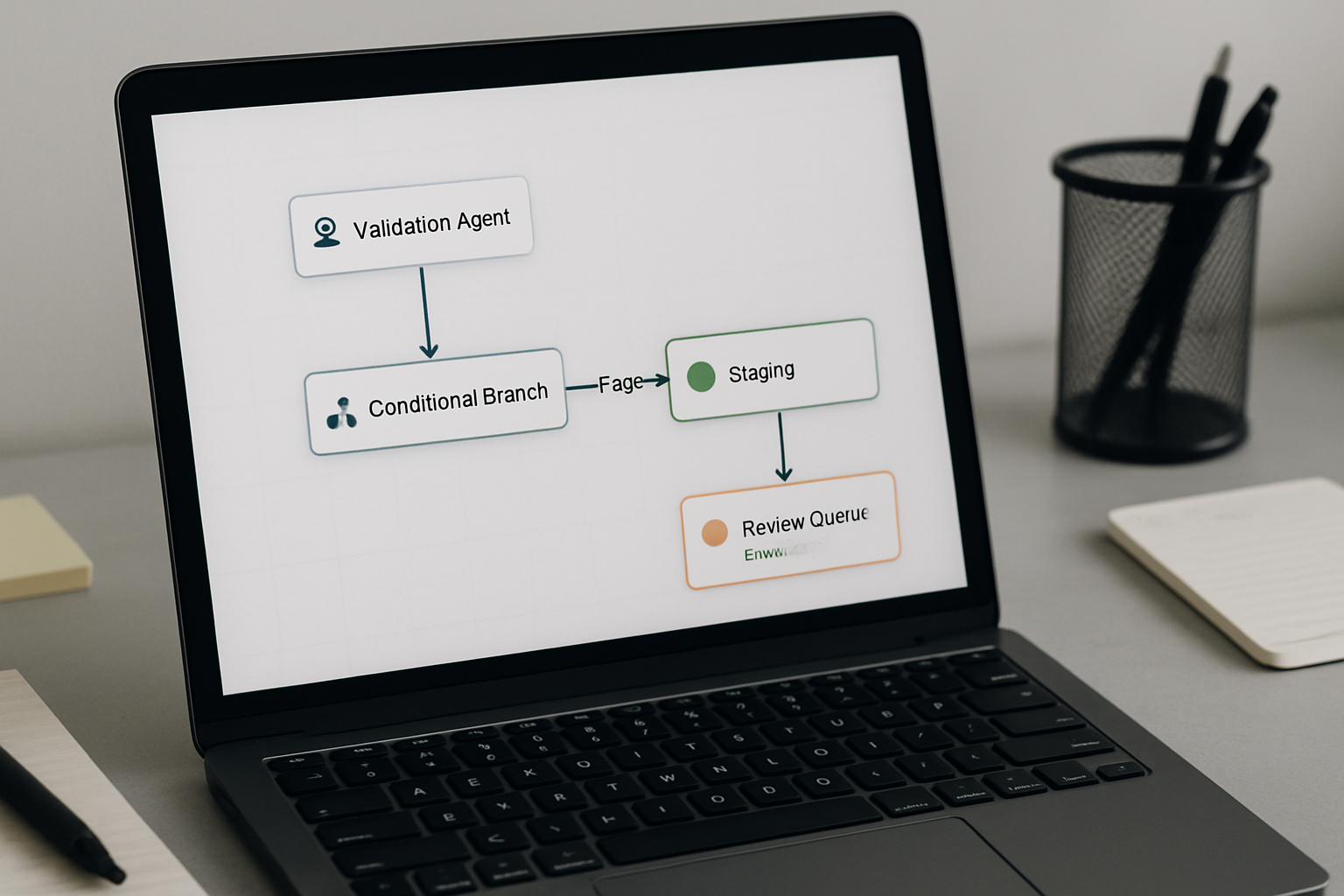
After: Validation Agent Inserted Before Staging
The corrected flow: brief → draft agent → validation agent node → scored output → conditional routing → human review only for flagged posts → staging → publish.
The validation agent does not rewrite. It scores. It checks the output against a defined rubric: structural completeness, tone consistency against a stored reference sample, keyword density within bounds, and a basic originality check against previously published content in the same cluster. Posts that pass the threshold route to staging automatically. Posts that fail route to a review queue with a failure reason attached.
The human review burden dropped from every post to roughly the flagged minority. That is the numeric shift that matters — not total time saved, but where the human attention actually lands.
Workflow Comparison
STAGE: Human Review
Manual: Every post — roughly 10–15 min each at scale
With QA Agent: Flagged posts only — typically 20–30% of output
Effect: Human attention concentrates on actual problems
STAGE: Pattern Drift Detection
Manual: Noticed weeks late — after publishing
With QA Agent: Caught at draft stage before staging
Effect: Drift corrected before it compounds
STAGE: Failure Diagnosis
Manual: Vague — “the post feels off”
With QA Agent: Specific — failure reason attached to flagged post
Effect: Faster correction, less guesswork
The Profit Angle: The real cost is not the time the AI takes to generate. It is the time a person quietly spends correcting output that was never flagged, never logged, and never counted as a quality failure.
Building the Validation Agent Node
The setup is simpler than it sounds, but the hard part is not the technical implementation. It is deciding what the rubric actually measures.
Step 1: Define the scoring dimensions
The agent needs a closed scoring rubric. Vague instructions produce vague scores. A working rubric looks like this:
- Structure check: Does the post contain all required sections? (hook, decision point, at least one execution block, closing insight)
- Tone check: Does the opening paragraph match the stored reference tone sample? Score 1–5.
- Originality check: Does the post share more than X% structural similarity with any post published in the last 90 days in the same cluster?
- Keyword density check: Is the primary keyword present within the first 100 words and at least twice in the body without obvious stuffing?
Step 2: Set the pass threshold and routing logic
A post that scores below threshold routes to a review queue. A post that passes routes directly to staging. The routing is conditional, not manual. In a tool like Make, n8n, or a custom LangChain chain, this is a simple branch node.
Example n8n routing logic (plain language):
→ route to: staging_queueELSE
→ route to: human_review_queue
→ attach: failure_reason (from agent output)
→ tag: review_needed
Step 3: Build the validation prompt
The agent prompt must be structured, not conversational. A working version:
– structure_score: 1–5 (all required sections present and ordered correctly)
– tone_score: 1–5 (matches reference tone sample below)
– originality_flag: true/false (true = too similar to reference cluster)
– keyword_present: true/false
– failure_reason: string (empty if all scores pass, specific if any fail)
Reference tone sample: [insert 150-word sample from best-performing post]
Post to evaluate: [insert draft output]
Output format: {“structure_score”: X, “tone_score”: X, “originality_flag”: X, “keyword_present”: X, “failure_reason”: “…”}
The JSON output requirement is non-negotiable. If the agent returns narrative text instead of structured output, the routing node cannot parse it. Add a validation step in the workflow that checks the output is parseable JSON before the branch logic fires.
Failure condition to watch for: The agent scores every post as passing because the rubric criteria are too vague. If failure_reason is always empty, the rubric is not specific enough. Tighten the scoring definitions, not the model temperature.
The Scenario That Exposes the Real Risk
The flow assumption going in: brief → draft → QA agent → staging. Clean. Linear.
It was not. The first failure point appeared at the tone score. The reference tone sample was pulled from a post written six months earlier. The brand voice had shifted since then. The agent was scoring new posts against an outdated benchmark, flagging good posts and passing posts that had already drifted.
The fix: the reference tone sample must be updated on a defined cadence — roughly once per content cycle or after any deliberate editorial shift. It is not a set-and-forget input. Treat it like a living document.
The corrected scenario:
Brief → draft agent → validation agent (with current tone reference) → JSON score output → conditional routing → flagged posts to review queue with failure reason → staging for passed posts → publish. Roughly 2–3 minutes of automated processing per post, with human attention reserved for the flagged minority.
Second failure condition: The originality check fires false positives when posts cover the same topic cluster. Posts about the same keyword group will share structural and lexical overlap by design. Set the similarity threshold with enough headroom that legitimate cluster content passes, or filter the comparison set to exclude posts from the same topic cluster.
What This Does Not Solve
The QA agent catches structural and tonal drift. It does not catch factual errors. If the draft agent generates a plausible-sounding but incorrect claim, a scoring rubric will not flag it unless you build a specific fact-check node — which is a separate agent with its own complexity.
It also does not solve prompt rot. If the original draft prompt was weak, the agent will score the output of a weak prompt against a rubric and pass it. Garbage in, validated garbage out. The QA gate is a filter, not a correction engine.
If the workflow changes frequently — new formats, new brand guidelines, new content types — the rubric will lag. A QA agent calibrated for one content format will misfire on another. This setup works best when the production process is stable. If you are still experimenting with format and voice, building the QA layer first is premature.
And for very small operations — under ten posts per cycle — the manual review step is probably faster than the setup cost. This is overkill until volume makes manual review genuinely impossible.

The Fix Checklist
- Audit the last production cycle: count posts that had a documented human review outcome. If zero, that is the problem.
- Define a closed scoring rubric with 4–5 specific dimensions. Avoid vague criteria like “quality” or “readability” — score structural completeness, tone match, originality, and keyword presence.
- Pull a current tone reference sample (150–200 words from a recent best-performing post). Update this sample every content cycle.
- Build the validation agent node with a JSON-output prompt. Test the output is parseable before connecting the branch logic.
- Set the routing threshold. Route passes to staging. Route failures to a review queue with failure_reason attached.
- Set the originality similarity threshold with cluster-aware headroom to avoid false positives on related-topic posts.
- Schedule a rubric review every 30 days or after any deliberate editorial change. The rubric is not permanent.
Get the QA Agent Setup Notes
The next breakdown covers the full validation prompt template, the n8n routing config, and the tone reference update schedule. Join the list to get it when it drops.