Not because the model was broken. Not because the temperature was too high. The prompt had no schema. The model filled that gap with prose, trailing commas, and markdown fences wrapped around JSON that was never meant to be markdown. Every downstream step that depended on that output either errored out or silently accepted malformed data and continued — which is worse.
This is the pattern. The visible failure is a parser error. The actual cause is one layer upstream: the prompt never told the model what the output must look like.
The Wrong Diagnosis
The first assumption is almost always model instability. The output is inconsistent, so the model must be the problem. Raise the context, switch models, lower the temperature — the fixes target the symptom, not the cause.
The parser broke twice before the actual cause was identified. The prompt had no strict schema definition and no explicit rule against prose. The model was doing exactly what it was built to do: generating helpful, readable output. That output just happened to include an explanation before the JSON, a note after it, and occasionally a key wrapped in a markdown header instead of a string.
Temperature set to 0.1 helped reduce variance. It did not fix the root problem. A model with low temperature will still add a preamble if the system prompt does not explicitly prohibit it. The fix was not a model setting. It was a constraint.
Wrong assumption → correction: “The model is inconsistent” → The prompt gave the model room to be inconsistent. Remove the room.
Before and After: What the Prompt Actually Said
This is the before version. It looks reasonable. It still produced broken output on roughly every third run where the input was slightly longer or more ambiguous.
Extract the company name, contact email, and plan tier from the input. Return the result as JSON.
Model output: “Sure! Here is the extracted data: “`json\n{\”company\”: \”Acme\”, \”email\”: \”hello@acme.io\”, \”plan\”: \”pro\”}“`”
Parser result: SyntaxError — unexpected token
You are a data extraction engine. Output ONLY valid JSON. No prose. No markdown fences. No explanation before or after. No trailing commas. Use exactly this schema:
{
"company": string,
"email": string,
"plan": "free" | "pro" | "enterprise",
"extraction_confidence": "high" | "low"
}
If a field cannot be determined, set its value to null. Do not invent values.
Model output: {“company”: “Acme”, “email”: “hello@acme.io”, “plan”: “pro”, “extraction_confidence”: “high”}
Parser result: clean parse, zero errors
The difference is not clever prompting. It is removing ambiguity about what the output contract looks like. Structure is a constraint, not a suggestion — and the model will not apply it unless you enforce it explicitly.
Copy the after-version schema block into your system prompt. Replace the field names and types with your actual output requirements. Keep the “No prose. No markdown fences. No explanation” rules exactly as written.
The Validation Step You Cannot Skip
Enforcing the schema in the prompt reduces failure rate significantly. It does not eliminate it. Any production pipeline that trusts model formatting without a validation layer is one edge case away from silent data corruption downstream.
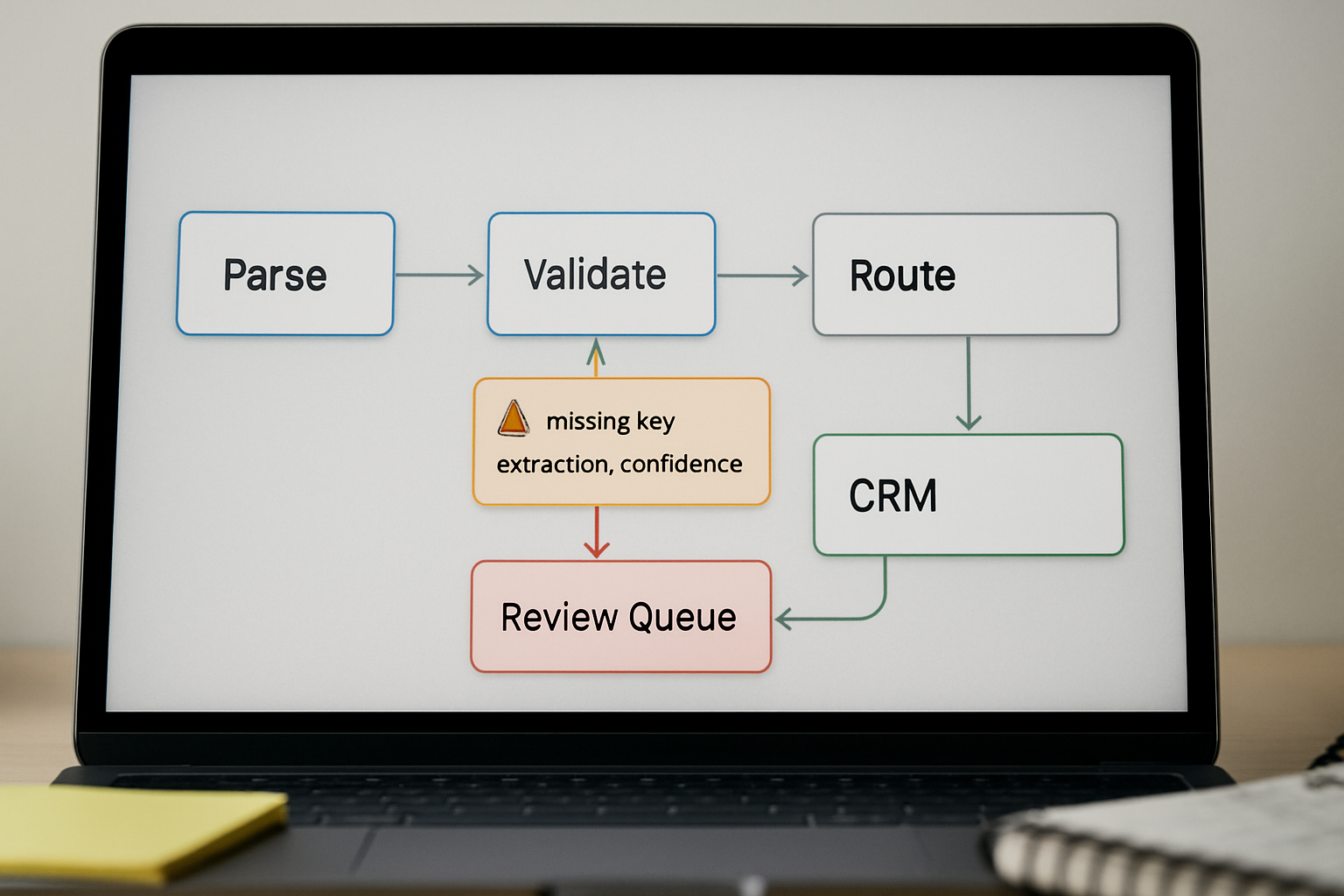
The validation step must happen at the boundary — before the output touches any downstream node, CRM field, or API call.
Minimal validation sequence
- Parse the raw string. Wrap
JSON.parse()or equivalent in a try/catch. If it throws, route immediately to the fallback handler. Do not continue. - Check required keys. Confirm every mandatory field exists and is not
undefined. A key missing from the response is a schema violation, even if the JSON itself parsed cleanly. - Validate closed-set values. If
planmust be one of"free" | "pro" | "enterprise", reject anything outside that set. A model returning"starter"or"Pro"(capitalized) breaks downstream logic silently if you do not check. - Check null handling. Confirm your downstream step can accept null on optional fields. If it cannot, route those responses to review before they enter the system.
In a Node.js environment, this validation block takes fewer than 20 lines. In Python, a Pydantic model handles steps 2 through 4 automatically once you define the schema class. In n8n or Make, a Code node runs the parse and key-check before the next module fires.
Operational signal: If your validation gate rejects more than 1 in 20 responses under normal load, the system prompt schema is still underspecified. Return to the prompt before adjusting anything else.
Fallback Handling That Actually Works
The instinct is to retry immediately. That is usually the right call — but only once, and only with a modified prompt. Retrying with the identical prompt that already produced malformed output will produce malformed output again at the same rate.
A workable fallback sequence
- First attempt fails validation → log the raw output with a
parse_failedflag and the failure reason attached. - Retry once with the same system prompt plus an appended user message: “Your previous response was not valid JSON. Return only the JSON object with no surrounding text.”
- Second attempt fails → route to a human review queue. Do not retry a third time automatically. Two consecutive failures usually indicate an input-side problem, not a model variance issue.
- Log both attempts with the original input. The pattern of what inputs trigger failures will tell you where the schema needs to be more explicit.
try {
result = JSON.parse(model_output);
validate_schema(result); // throws if keys missing or values out of set
pass_to_next_step(result);
} catch (e) {
log({ input, raw_output: model_output, failure_reason: e.message, attempt: 1 });
retry_output = call_model(input, prompt + "\nReturn only the JSON object. No prose.");
try {
result = JSON.parse(retry_output);
validate_schema(result);
pass_to_next_step(result);
} catch (e2) {
route_to_review_queue({ input, raw_output: retry_output, failure_reason: e2.message });
}
}
The review queue entry must include the failure reason, not just a flag. “Missing key: extraction_confidence” is actionable. “Parse failed” is not.
What This Looks Like at Scale
AI returns variable output → parser errors surface intermittently → someone checks logs manually → roughly 15–30 minutes of silent correction per day on moderate volume
Valid output passes instantly → malformed output routes to review with failure_reason attached → human time drops to reviewing flagged edge cases only, typically a few per week
The Profit Angle: the real cost of skipping schema enforcement is not the parser error — it is the person quietly fixing AI output every morning before anyone notices the workflow “runs fine.”
At low volume, inconsistent JSON is annoying. At scale — hundreds of records per day, multi-step pipelines, CRM writes — a single malformed key silently corrupts a data field that does not surface as an error for days. By then the source is difficult to trace.
The validation gate is not overhead. It is the only thing that makes the automation trustworthy enough to leave unsupervised.
Where This Breaks
Schema enforcement solves the formatting problem. It does not solve the content problem.
- The JSON is valid but the values are wrong. A model can return perfectly structured JSON with
"extraction_confidence": "high"on an input where the company name was genuinely ambiguous. Validation passes. The data is still bad. Schema enforcement cannot catch semantic errors — only structural ones. - Very long or complex inputs. When the input pushes the model toward its context limits, output quality degrades in ways that schema enforcement cannot prevent. The model may truncate, hallucinate a field, or return a partial object that technically parses. Add an output length check for critical fields when inputs are consistently long.
- Closed-set fields with high variance inputs. If real-world inputs contain plan tiers outside your defined set, the model will either hallucinate a match or return null. Neither is wrong — but your downstream system needs to handle both states explicitly before they reach production.
- Models without reliable instruction-following. Smaller or fine-tuned models with weaker instruction adherence will ignore the “No prose” rule more often. Temperature 0.1 helps but does not eliminate this. If the validation reject rate stays above roughly 5% after schema enforcement, consider whether the model is appropriate for structured output tasks.
If the failure pattern is content accuracy rather than format, schema enforcement is the wrong layer to fix it. That is a prompt refinement and grounding problem, not a JSON structure problem.
The Checklist Before You Ship
- System prompt includes explicit schema with field names, types, and allowed values for closed sets
- System prompt includes “No prose. No markdown fences. No explanation before or after the JSON object.”
- Temperature set to 0.1 or lower for structured output calls
- Validation runs at the boundary before any downstream step receives the output
- Validation checks: JSON parses cleanly → required keys present → closed-set values within allowed range → nulls handled
- Fallback retries once with an amended prompt, then routes to review queue on second failure
- Review queue entries include failure_reason, not just a flag
- Validation reject rate monitored — above roughly 5% signals the schema or prompt needs refinement
Get the structured output prompt pack
The schema block, validation sequence, and fallback handler from this article — formatted as copy-paste assets for n8n, Make, and direct API calls. Join the list and get the setup notes sent directly.
The parser was never the problem. The moment you stop trusting the model to format its own output and start treating the schema as a hard contract, the failures become predictable — and predictable failures can be handled automatically.