The chain ran. The LLM returned something that looked exactly like valid JSON. And then the parser threw OutputParserException: Could not parse output and the whole workflow stopped.
Not because the model failed to follow instructions. Not because the schema was wrong. The model wrapped the JSON in a markdown code fence — three backticks, a language tag, the object, three more backticks — and the parser’s regex found nothing it recognized. One formatting artifact. Complete chain failure downstream.
This is the failure pattern that causes the most wasted debugging time with LangChain output parsers, because the output looks correct when you read it. The problem only becomes visible when you trace what the parser actually receives versus what it expects.
What the Failure Actually Looks Like
Here is the setup that breaks silently in production. A StructuredOutputParser is wired to a prompt template, the chain runs, and the exception surfaces:
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
response_schemas = [
ResponseSchema(name="product_name", description="Name of the product"),
ResponseSchema(name="sentiment", description="positive, negative, or neutral"),
ResponseSchema(name="confidence", description="score between 0 and 1")
]
parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = parser.get_format_instructions()
prompt = PromptTemplate(
template="Analyze this review and return structured data.\n{format_instructions}\n\nReview: {review}",
input_variables=["review"],
partial_variables={"format_instructions": format_instructions}
)
llm = ChatOpenAI(model="gpt-4o", temperature=0)
chain = prompt | llm | parser
result = chain.invoke({"review": "This product exceeded all expectations."})
The LLM response that arrives at the parser looks like this:
```json
{
"product_name": "unspecified",
"sentiment": "positive",
"confidence": 0.95
}
```
And the exception output:
langchain_core.exceptions.OutputParserException:
Got invalid return object. Expected markdown code snippet with JSON
in it, but got:
```json
{
"product_name": "unspecified",
...
Could not parse output: ```json
{
"product_name": "unspecified",
"sentiment": "positive",
"confidence": 0.95
}
```
The regex that StructuredOutputParser uses expects a specific fence format. When the model produces a slightly different variant — different fence markers, extra text before the JSON block, or a trailing explanation sentence after the closing brace — the match fails entirely. Every field in your schema comes back as nothing, and whatever downstream node was expecting result["sentiment"] throws a KeyError on the next step.
At scale, this is not an occasional edge case. Models with higher temperature settings, models that received ambiguous instructions, or chains where the format instructions got truncated by a context window will produce this failure regularly.
The Wrong Diagnosis Most People Make
The first instinct is usually to inspect the prompt. Add more explicit instructions. Tell the model not to use markdown. Repeat the schema definition. None of that reliably prevents the problem because you cannot fully control how a chat model formats its response across every run, every model version, and every edge case in the input.
The second instinct is to switch to a different parser and assume the problem goes away. It does not — not unless the replacement parser is structurally more resilient, or unless you add a recovery layer.
What actually needs to change is the assumption that a single-pass parser is sufficient for production use. It is not. The parser needs either a fallback mechanism that attempts to repair malformed output, or the entire output contract needs to be enforced at the model level rather than the parsing level.
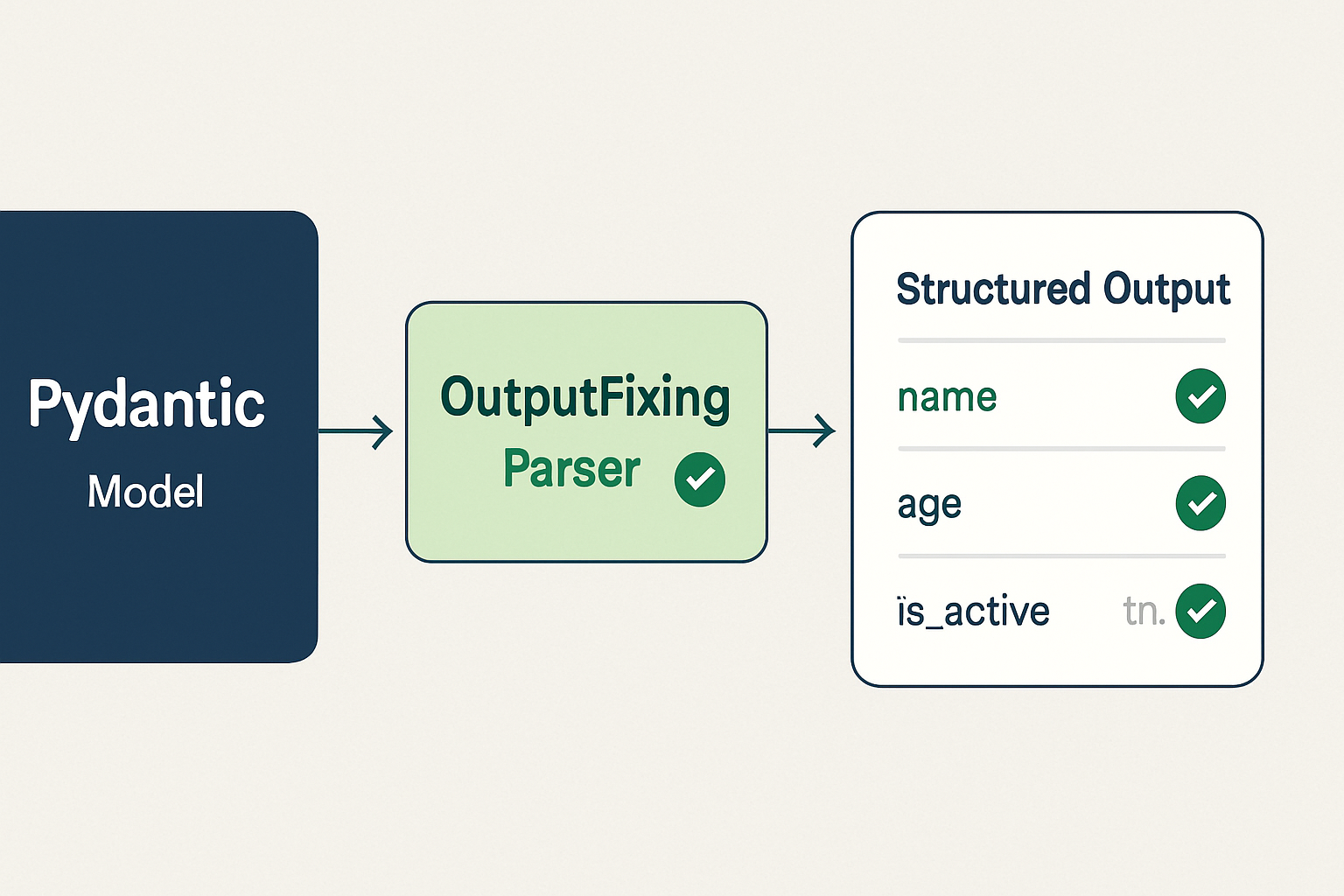
Fix 1: OutputFixingParser as a Recovery Layer
OutputFixingParser wraps your existing parser and fires a second LLM call when parsing fails. That second call receives the malformed output and the original schema, and attempts to return a corrected version. It adds latency and a small token cost per failure, but it eliminates the hard crash.
from langchain.output_parsers import StructuredOutputParser, ResponseSchema, OutputFixingParser
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
response_schemas = [
ResponseSchema(name="product_name", description="Name of the product"),
ResponseSchema(name="sentiment", description="positive, negative, or neutral"),
ResponseSchema(name="confidence", description="score between 0 and 1")
]
base_parser = StructuredOutputParser.from_response_schemas(response_schemas)
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# Wrap the base parser with a fixing layer
fixing_parser = OutputFixingParser.from_llm(parser=base_parser, llm=llm)
format_instructions = base_parser.get_format_instructions()
prompt = PromptTemplate(
template="Analyze this review and return structured data.\n{format_instructions}\n\nReview: {review}",
input_variables=["review"],
partial_variables={"format_instructions": format_instructions}
)
chain = prompt | llm | fixing_parser
result = chain.invoke({"review": "This product exceeded all expectations."})
print(result)
# Output: {'product_name': 'unspecified', 'sentiment': 'positive', 'confidence': 0.95}
When the first parse attempt fails, OutputFixingParser sends a repair prompt to the LLM, receives a corrected JSON string, and parses that instead. The chain continues without an exception. The real ROI here is not that failures disappear — it is that one transient formatting artifact no longer requires a human to diagnose and restart a production workflow.
One operational note: OutputFixingParser does not validate that the corrected output is semantically correct, only that it parses. If the model’s repair introduces a wrong value, the chain will proceed with bad data rather than surfacing an error. Add downstream validation on critical fields if that matters for your use case.
Fix 2: PydanticOutputParser for Schema Enforcement
The more durable fix is replacing StructuredOutputParser with PydanticOutputParser. Pydantic models enforce types, constraints, and field presence at parse time — not just structure. A field typed as float that comes back as a string will either coerce correctly or raise a validation error you can catch and handle explicitly.
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from typing import Literal
class ReviewAnalysis(BaseModel):
product_name: str = Field(description="Name of the product")
sentiment: Literal["positive", "negative", "neutral"] = Field(
description="Sentiment classification"
)
confidence: float = Field(
ge=0.0, le=1.0,
description="Confidence score between 0 and 1"
)
parser = PydanticOutputParser(pydantic_object=ReviewAnalysis)
llm = ChatOpenAI(model="gpt-4o", temperature=0)
prompt = PromptTemplate(
template="Analyze this review.\n{format_instructions}\n\nReview: {review}",
input_variables=["review"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
chain = prompt | llm | parser
result = chain.invoke({"review": "This product exceeded all expectations."})
print(result.sentiment) # positive
print(result.confidence) # 0.95
print(type(result)) #
The output is a typed Python object, not a dictionary. Downstream code that accesses result.sentiment instead of result["sentiment"] will catch schema drift at the access point rather than silently propagating a wrong value. The Literal type on sentiment means any value outside the allowed set raises a ValidationError immediately — which is far easier to debug than a downstream branch that silently routed to the wrong path because the field came back as "Positive" with a capital P.
Combine PydanticOutputParser with OutputFixingParser the same way as before when you need both type enforcement and automatic recovery:
from langchain.output_parsers import OutputFixingParser
fixing_parser = OutputFixingParser.from_llm(
parser=PydanticOutputParser(pydantic_object=ReviewAnalysis),
llm=llm
)
chain = prompt | llm | fixing_parser
result = chain.invoke({"review": "Terrible quality, broke after one day."})
print(result.sentiment) # negative
print(result.confidence) # 0.87
Fix 3: JsonOutputParser and the Function Calling Alternative
JsonOutputParser is the most permissive option. It strips markdown fences, attempts to extract any valid JSON from the response, and returns a plain dictionary. No schema enforcement, no Pydantic validation — just parsing. Useful when the schema is dynamic or when you need to handle heterogeneous outputs, but it will silently pass through structurally wrong responses without complaint.
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o", temperature=0)
parser = JsonOutputParser()
prompt = ChatPromptTemplate.from_messages([
("system", "Return a JSON object with fields: product_name, sentiment, confidence."),
("human", "{review}")
])
chain = prompt | llm | parser
result = chain.invoke({"review": "Absolutely love it."})
print(result) # {'product_name': 'unspecified', 'sentiment': 'positive', 'confidence': 0.9}
For production pipelines where schema correctness is non-negotiable, the most reliable path is using the .with_structured_output() method available on newer LangChain chat models. This routes through the model’s native function calling or tool use API, which means the JSON is enforced at the model layer before it reaches any parser:
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from typing import Literal
class ReviewAnalysis(BaseModel):
product_name: str = Field(description="Name of the product")
sentiment: Literal["positive", "negative", "neutral"]
confidence: float = Field(ge=0.0, le=1.0)
llm = ChatOpenAI(model="gpt-4o", temperature=0)
structured_llm = llm.with_structured_output(ReviewAnalysis)
result = structured_llm.invoke("Analyze: This product exceeded all expectations.")
print(result.sentiment) # positive
print(result.confidence) # 0.95
When .with_structured_output() is available for your model, it eliminates the fence-stripping problem entirely. The model returns structured data through the API’s native mechanism rather than formatting JSON as text. Parsing failures from markdown artifacts become impossible because there is no text to misformat.
Parser Types: When to Use Which
StructuredOutputParser is the fastest way to get started and the most fragile in production. It uses regex-based fence matching, has no type validation, and breaks when the model adds any text outside the expected fence pattern. Use it for internal prototypes or low-stakes pipelines where a restart is acceptable.
PydanticOutputParser adds field types, constraints, and closed-set validation via Literal. It raises explicit ValidationError exceptions when the schema is violated, which makes debugging significantly faster. Pair it with OutputFixingParser for production use. The tradeoff is that it requires a Pydantic model definition upfront — not practical for dynamic schemas.
JsonOutputParser is the most permissive. It handles fence stripping and returns a dictionary, but it does not validate structure or types. Appropriate when you need flexibility or when downstream code handles validation separately. It will not catch a missing field or a wrong type — those errors surface later, usually in the wrong place.
.with_structured_output() is the correct choice for any pipeline where schema correctness is required and the model supports function calling. It removes the parsing layer entirely. The only reason not to use it is model compatibility — not every model supports it, and it is not available in every LangChain integration.
The Cascade That Breaks Downstream
The reason this failure pattern matters beyond the immediate exception is what happens two or three nodes after the parser. A typical chain that processes the parsed output might route based on result["sentiment"], write result["confidence"] to a database, or pass result["product_name"] to a summarization step. When the parser fails silently — or when OutputFixingParser repairs the structure but not the semantics — every downstream node operates on wrong or missing data.
result.get("sentiment", None) as None, and every record defaulted to the fallback branch — including the ones that should have been flagged as high-confidence negatives. The failure was invisible until the database showed uniform routing.PydanticOutputParser with OutputFixingParser: the Literal constraint on sentiment caused explicit ValidationError on any response outside the allowed set, the fixing layer corrected fence artifacts before they reached the validator, and downstream routing reflected actual model output rather than a default fallback.The cascade does not announce itself. It shows up as data quality problems — wrong routing rates, skewed aggregations, silent defaults — roughly one to two pipeline generations after the parsing step. By then, the root cause is harder to trace.
Debugging Checklist for JSON Schema Mismatches
- Print the raw LLM output before it hits the parser by temporarily removing the parser from the chain and logging the string. Confirm whether the model is returning markdown fences, extra explanation text, or a truncated JSON object.
- Check whether
get_format_instructions()output is actually reaching the prompt by printing the formatted prompt string before the chain runs. If the instructions were truncated by a context window limit, the model had no schema contract to follow. - Verify that all required fields in the schema appear in the LLM output. A missing field does not always raise an immediate exception — it may silently default to
Nonedepending on the parser and how downstream code accesses the result. - If using
PydanticOutputParser, confirm that field types in the model match what the LLM is likely to produce. A field typed asfloatreceiving the string"0.95"will coerce correctly in most Pydantic versions, but a field typed asLiteral["positive", "negative", "neutral"]receiving"Positive"will raise aValidationError— which is the correct behavior, not a bug. - When
OutputFixingParseris active, add a logging wrapper around the fixing call to track how often it fires. If it is activating on more than roughly 10–15% of runs, the prompt is not giving the model a clear enough output contract and the format instructions need to be more explicit or the model temperature needs to be reduced. - Test
.with_structured_output()directly against your model before assuming it is unavailable. For OpenAI models on recent LangChain versions, it is typically the most stable path and requires no custom parser logic.
Where This Breaks
OutputFixingParser adds a second LLM call on every failure. For a pipeline running thousands of requests per hour, that repair cost accumulates. If the underlying prompt is consistently producing malformed output — rather than failing occasionally — the fix layer becomes a tax on a broken prompt, not a safety net for edge cases. Address the prompt first.
PydanticOutputParser requires a static schema defined at build time. Any pipeline that needs to handle dynamic field sets, user-defined schemas, or heterogeneous outputs will hit the limits of this approach quickly. JsonOutputParser is more practical there, but you lose type enforcement and need to handle validation elsewhere.
.with_structured_output() is not available on all models and not fully stable across all LangChain provider integrations. Local models, some open-source integrations, and older API versions may not support it. Check the specific model and LangChain version before building a pipeline that depends on it.
None of these parsers solve the problem of the model returning a structurally valid but semantically wrong response — a confidence score of 1.0 on every record, a sentiment field that never returns "negative" regardless of input, or a product name that hallucinated something unrelated. Schema compliance and semantic accuracy are separate problems. Parsers handle the first. Evaluation and validation gates handle the second.
If the debugging checklist above pointed to fence artifacts as the root cause, the fix sequence is: switch to PydanticOutputParser, wrap with OutputFixingParser, and monitor the repair rate. If the repair rate stays above 10%, reduce temperature and tighten the format instructions in the prompt. If the model supports it, move to .with_structured_output() and skip the parsing layer entirely.
Get the full parser setup notes — including the Pydantic model templates and the OutputFixingParser configuration — sent directly: join the list for the workflow breakdown.
If the repair rate is low and the pipeline is stable, the checklist is done. If qualified records are still routing to the wrong branch, the schema is validating structure but not catching a semantic drift in the model’s output — and that is a different layer to fix.